
Redis 11 - Comment déployer et superviser Redis Enterprise et une application avec l'opérateur dans AKS
• •

Nous allons voir comment déployer et superviser un cluster Redis Enterprise, des bases Redis et une application dans Azure Kubernetes Services (AKS), à l’aide de l’opérateur Redis pour Kubernetes (K8S), Prometheus et Grafana.
Vous pouvez trouver des liens vers les enregistrements vidéo et les supports imprimables associés à la fin de cet article.
- Vidéo
- Prérequis
- Opérateur Redis Enterprise
- Déploiement de Redis Enterprise
- Supervision
- Déploiement d’une application
- Supports et liens
- Notes de bas de page
Vidéo
Les étapes sont inspirées de la documentation officielle1, à la date du 27/01/2023.
Prérequis
Il faut disposer d’un cluster Azure Kubernetes Services (AKS) dans Azure. La création de ce cluster est visible dans la vidéo accompagnant cet article.
Opérateur Redis Enterprise
Récupération des fichiers modèles
Commençons par récupérer les fichiers d’exemples depuis le dépôt GitHub2 pour éviter de devoir les resaisir.
git clone https://github.com/RedisLabs/redis-enterprise-k8s-docs.git
Création d’un espace de nommage
Nous allons déployer Redis Enterprise dans un espace de nommage. Cet espace peut être dédié exclusivement à un cluster Redis Enterprise ou bien être celui d’une application. Il ne peut y avoir qu’un seul cluster Redis Enterprise par namespace, en revanche, il peut y avoir plusieurs namespaces avec un cluster dans chacun. Enfin, les bases crées et hébergées dans un cluster, dans un namespace peuvent être exposées et accessibles depuis d’autres namespaces.
kubectl create namespace redisns
Comme nous allons principalement travailler dans ce namespace, nous le configurons comme namespace par défaut dans notre contexte.
kubectl config set-context --current --namespace=redisns
Déploiement de l’opérateur
Tout d’abord, nous devons identifier la dernière version disponible afin de l’installer.
VERSION=`curl --silent https://api.github.com/repos/RedisLabs/redis-enterprise-k8s-docs/releases/latest | grep tag_name | awk -F'"' '{print $4}'`
Ensuite, nous pouvons demander à kubernetes d’installer cette version de l’opérateur directement depuis l’URL.
kubectl apply -f https://raw.githubusercontent.com/RedisLabs/redis-enterprise-k8s-docs/$VERSION/bundle.yaml
Enfin, nous pouvons vérifier le bon déroulement de l’installation.
kubectl get deployment redis-enterprise-operator
Activation du controleur d’admission
L’opérateur utilise les fichiers de description, les CRDs, comme configuration à mettre en place et à maintenir. Les fichiers CRD sont au format YAML et suivent une syntaxe stricte. Le controleur d’admission a pour tâche de vérifier la validité syntaxique de ces fichiers et leur cohérence par rapport au contexte actuel du cluster, pour refuser tout changement qui serait impossible à réaliser. Cela permet d’éviter de casser une configuration qui fonctionne. Il faut récupérer le certificat auto-signé généré à la création du cluster depuis un des secrets K8S pour le faire prendre en compte par le pod d’admission grâce à un modèle de fichier YAML.
kubectl get secret admission-tls
CERT=`kubectl get secret admission-tls -o jsonpath='{.data.cert}'`
sed 's/NAMESPACE_OF_SERVICE_ACCOUNT/redisns/g' admission/webhook.yaml | kubectl create -f -
cat > modified-webhook.yaml <<EOF
webhooks:
- name: redb.admission.redislabs
clientConfig:
caBundle: $CERT
admissionReviewVersions: ["v1beta1"]
EOF
kubectl patch ValidatingWebhookConfiguration redb-admission --patch "$(cat modified-webhook.yaml)"
Par défaut, le controleur d’admission surveille les CRDs de tous les espaces de nommage. On peut le restreindre à certain espaces de nommage, mais je ne le ferai pas dans cet article.
Déploiement de Redis Enterprise
Création du cluster
Nous allons demander à l’opérateur d’effectuer les opérations nécessaires pour atteindre et maintenir la configuration décrite dans un fichier CRD de description de cluster. Nous allons indiquer le nombre de nœuds du cluster, la quantité de RAM et de CPU souhaitée pour chaque nœud et donner un nom à ce cluster. Nous choisissons 3 nœuds, ce qui est le minimum pour avoir la haute-disponibilité et le minimum géré par l’opérateur. Nous indiquons que nous voulons que chaque nœud dispose de 10Go de RAM. Cette configuration est inférieure aux préconisations officielles de production mais fera l’affaire pour la démonstration.
cat <<EOF | kubectl apply -f -
apiVersion: "app.redislabs.com/v1"
kind: "RedisEnterpriseCluster"
metadata:
name: my-rec
spec:
nodes: 3
redisEnterpriseNodeResources:
limits:
cpu: 2000m
memory: 10Gi
requests:
cpu: 2000m
memory: 10Gi
EOF
L’opérateur constate la présence d’un changement de configuration souhaitée dans le fichier CRD et va tenter de l’appliquer. Nous pouvons vérifier la configuration des clusters Redis Enterprise (REC, Redis Enterprise Clusters).
kubectl get rec
Ensuite, nous attendons que tous les pods soient créés, initialisés par un premier container et éxécutant un second container.
kubectl rollout status sts/my-rec
Finallement, il est possible de vérifier le déploiement complet :
kubectl get all
Le cluster Redis Enterprise dispose d’une interface web d’administration. Si nous n’avons pas défini d’informations de connexion (identifiant et mot de passe), l’opérateur en a créé pour nous dans des secrets Kubernetes. Nous allons donc les récupérer pour nous connecter à l’interface web :
kubectl get secret
kubectl get secret/my-rec -o jsonpath='{.data.password}' | base64 --decode
kubectl get secret/my-rec -o jsonpath='{.data.username}' | base64 --decode
kubectl port-forward service/my-rec-ui 8443:8443
La dernière commande permet d’exposer le service d’administration web depuis le cluster Kubernetes vers notre poste de travail pour nous y connecter avec un navigateur sur l’URL https://localhost:8443
Création d’une base de données
Nous pouvons ensuite décrire la base que nous souhaitons dans un fichier de description CRD. La plupart des options de configuration d’une base sont disponibles et disposent de valeurs par défaut. Je me contente d’indiquer :
- le nom de la base
- l’occupation maximale de la base en RAM
- le mode de persistance
- le nombre de shards maitres
- la réplication pour la haute-disponibilité
- le nom du cluster dans lequel je souhaite disposer de la base
cat << EOF | kubectl apply -f - apiVersion: app.redislabs.com/v1alpha1 kind: RedisEnterpriseDatabase metadata: name: smalldb spec: memorySize: 100MB persistence: "aofEverySecond" shardCount: 2 replication: true redisEnterpriseCluster: name: my-rec EOFOn peut utiliser la commande suivante pour vérifier la disponibilité de la base :
kubectl get redb smalldb -o jsonpath="{.status.status}"Dès que la base est disponible, elle est visible dans l’interface web d’administration et l’opérateur créée automatiquement un service Kubernetes dans l’espace de nommage d’utilisation de la base, celui de l’application qui va l’utiliser (que je n’ai pas spécifié ici).
kubectl get redb kubectl get svcSi aucune information n’a été prérenseignée, l’opérateur créée automatiquement un nom interne, choisit un port au hasard, créée un mot de passe généré et un nom de service à exposer. Toutes ces informations peuvent facilement être retrouvées dans Kubernetes.
kubectl get redb smalldb -o jsonpath="{.spec.databaseSecretName}" kubectl get secret/redb-smalldb -o jsonpath='{.data.password}' | base64 --decode kubectl get secret/redb-smalldb -o jsonpath='{.data.port}' | base64 --decode kubectl get secret/redb-smalldb -o jsonpath='{.data.service_name}' | base64 --decode
Modification d’une base
Maintenant que la base de données est créée, il est possible d’en changer la configuration. On peut le faire de différente manière :
- Accéder à l’interface web et modifier la configuration : ne jamais faire comme ça, les modification ne seraient pas dans le fichier CRD de description et l’opérateur chercherait à revenir à la configuration décrite.
- Par
kubectl apply, automatisable, sans interraction - Par
kubectl edit, interractive Voici la commande interractive, à titre d’exemple. Je n’illustrerai pas plus la modification de la configuration des bases ici.kubectl edit redb smalldb
Suppression d’une base
Il est évidemment possible de supprimer une base de données à l’aide de la commande suivante. Je ne la supprime pas tout de suite car je vais en avoir besoin dans les étapes suivantes.
kubectl delete redb smalldb
Démarrage d’un pod de benchmark
Nous pouvons maintenant démarrer un nouveau pod avec un conteneur de benchmark, tel que memtier_benchmark. Nous aurons besoin des informations de connexion à la base pour les transmettre à l’outil. Nous verrons plus loin comment industrialiser cette récupération, mais pour ce premier exemple, je les récupère dans des variables d’environnement locales.
DBNAME='smalldb'
DBSECNAME=`kubectl get redb "${DBNAME}" -o jsonpath="{.spec.databaseSecretName}"`
SVCNAME=`kubectl get secret/${DBSECNAME} -o jsonpath='{.data.service_name}' | base64 --decode`
SVCPORT=`kubectl get secret/${DBSECNAME} -o jsonpath='{.data.port}' | base64 --decode`
SVCPASS=`kubectl get secret/${DBSECNAME} -o jsonpath='{.data.password}' | base64 --decode`
et je les passe à l’application en ligne de commande. Il ne faut pas faire cela en production, car les informations apparaissent en clair si on affiche la liste des processus (ps -aux).
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: memtier
spec:
containers:
- name: memtier
image: redislabs/memtier_benchmark:latest
args: ["--key-prefix=a","--ratio=1:4","--test-time=120","-d","100","-t","2","-c","25","--pipeline=50","--key-pattern=S:S","--hide-histogram","-x","1000","-s","${SVCNAME}.redisns.svc","-p","${SVCPORT}","-a","${SVCPASS}"]
EOF
kubectl logs memtier
Supervision
Déploiement et intégration de Prometheus
Redis-Enterprise expose de nombreuses métriques concernant le cluster, les nœuds, les bases et les shards sous la forme d’un exporteur au format Prometheus pour que ce dernier puisse les collecter, les stocker et les représenter ou les servir à Grafana. On peut aussi utiliser Prometheus-Alertmanager pour superviser et déclencher des alertes.
Je ne vais pas couvrir un déploiement complet de prometheus, dans les règles de l’art ou avec son opérateur. On peut trouver de nombreux articles qui le font très bien, par exemple phoenixnap3 ou devopscube4.
L’opérateur a automatiquement créé des services Kubernetes pour exposer le point de connexion de l’exporteur au format Prometheus du cluster Redis Enterprise. Si vous n’avez pas installé de certificats personnalisés, l’opérateur a automatiquement créé des certificats auto-signés et ils faudra donc penser à l’option tls_config pour que prometheus puisse accéder à l’exporteur.
Prometheus dispose aussi d’un opérateur permettant la découverte et l’ajout automatique de sources à partir d’annotation ou de labels. Je ne couvre pas cette installation complète de Prometheus. Je ne fais qu’une installation basique pour illustrer la collecte des metriques du cluster, des nœuds, des bases et des shards Redis Enterprise.
Il faut inclure dans le fichier de configuration de prometheus une référence au nom du service prometheus du cluster. Ce nom est composé du nom du cluster postfixé par -prom :
scrape_configs:
- job_name: 'myrec'
scheme: https
static_configs:
- targets: ['my-rec-prom.redisns.svc:8070']
tls_config:
insecure_skip_verify: true
Commençons par créer un espace de nommage spécifique pour la supervision monitoring, dans lequel nous allons déployer Prometheus.
kubectl create namespace monitoring
Prometheus aurait théoriquement besoin de permissions pour accéder aux métriques exposées par Kubernetes. Bien que nous ne nous y intéressons pas, je vais quand même créer un compte de service, un role de cluster et une association entre ce compte et le role :
cat << EOF | kubectl create -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
EOF
cat << EOF | kubectl create -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
EOF
cat << EOF | kubectl create -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring
EOF
Ensuite, j’externalise le fichier de configuration de Prometheus à l’extérieur de son pod, dans une ConfigMap. C’est dans ce fichier de configuration qu’il faut inclure la définition du service Redis-Prometheus.
cat << EOF | kubectl create -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
rule_files:
# - "example-file.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'myrec'
scheme: https
static_configs:
- targets: ['my-rec-prom.redisns.svc:8070']
tls_config:
insecure_skip_verify: true
EOF
Je déploie un pod Prometheus. Dans le cadre de ce tutoriel, je ne configure pas de volume persistent. Prometheus perdra donc sa base si le pod redémarre. Autrement, il faudrait inclure une demande de persistance dans la configuration :
- name: prometheus-storage-volume
persistentVolumeClaim:
claimName: pvc-nfs-data
cat << EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitoring
labels:
app: prometheus
spec:
replicas: 1
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9090"
spec:
containers:
- name: prometheus
image: prom/prometheus
args:
- '--storage.tsdb.retention=6h'
- '--storage.tsdb.path=/prometheus'
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- name: web
containerPort: 9090
volumeMounts:
- name: prometheus-config-volume
mountPath: /etc/prometheus
- name: prometheus-storage-volume
mountPath: /prometheus
restartPolicy: Always
volumes:
- name: prometheus-config-volume
configMap:
defaultMode: 420
name: prometheus-config
- name: prometheus-storage-volume
emptyDir: {}
EOF
Je termine en exposant prometheus sous la forme d’un service Kubernetes pour pouvoir le manipuler plus facilement ensuite. J’ai fait le choix d’un service NodePort, dans la pratique, en production, on préfère parfois un LoadBalancer mais je voulais limiter les dépendances à la configuration Kubernetes du fournisseur :
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
namespace: monitoring
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '9090'
spec:
selector:
app: prometheus
type: NodePort
ports:
- port: 8080
targetPort: 9090
nodePort: 30909
EOF
Enfin, je connecte le service Prometheus du cluster à un port sur mon poste de travail pour m’y connecter depuis mon navigateur local http://localhost:8080 . Cette commande est blocante.
kubectl port-forward service/prometheus-service 9090:8080 -n monitoring
Déploiement et intégration de Grafana
Redis fournit des tableaux de bord Grafana prêts à l’emploi pour représenter et exploiter les métriques stockées dans Prometheus.
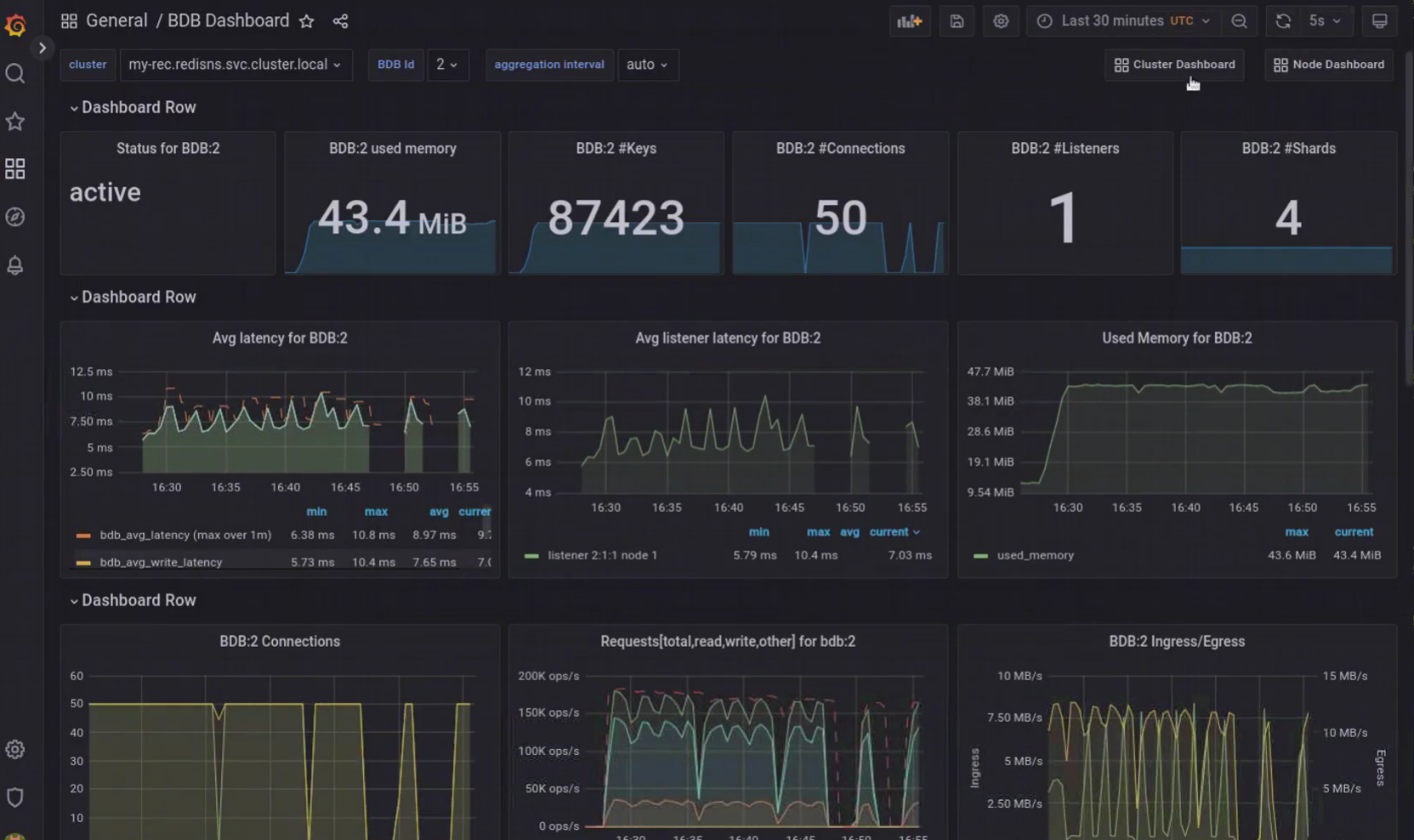
Tous comme pour Prometheus, mon but n’est pas de faire un tutoriel d’installation de Grafana sur Kubernetes dans les règles de l’art. Je me base donc sur l’article de blog de devopscube5.
Dans le même esprit que pour Prometheus, j’externalise la configuration de Grafana dans une ConfigMap pour ne pas la maintenir à l’intérieur des pods Grafana :
cat << EOF | kubectl create -f -
apiVersion: v1
kind: ConfigMap
metadata:
name: grafana-datasources
namespace: monitoring
data:
prometheus.yaml: |-
{
"apiVersion": 1,
"datasources": [
{
"access":"proxy",
"editable": true,
"name": "prometheus",
"orgId": 1,
"type": "prometheus",
"url": "http://prometheus-service.monitoring.svc:8080",
"version": 1
}
]
}
EOF
Tout comme pour Prometheus, je déploie Grafana, sans PersistentVolume, les pods perdent donc leurs données et les tableaux de bord configurés quand ils sont arrêtés :
cat << EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
name: grafana
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:latest
ports:
- name: grafana
containerPort: 3000
resources:
limits:
memory: "1Gi"
cpu: "1000m"
requests:
memory: 500M
cpu: "500m"
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
- mountPath: /etc/grafana/provisioning/datasources
name: grafana-datasources
readOnly: false
volumes:
- name: grafana-storage
emptyDir: {}
- name: grafana-datasources
configMap:
defaultMode: 420
name: grafana-datasources
EOF
J’expose Grafana en tant que Service Kubernetes pour le manipuler plus facilement :
cat << EOF | kubectl create -f -
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
annotations:
prometheus.io/scrape: 'true'
prometheus.io/port: '3000'
spec:
selector:
app: grafana
type: NodePort
ports:
- port: 3000
targetPort: 3000
nodePort: 32000
EOF
Et, finalement, je connecte le service Grafana depuis le cluster Kubernetes vers mon poste de travail pour y connecter mon navigateur. Cette commande est blocante :
kubectl port-forward service/grafana 3000 -n monitoring
Je peux me connecter à Grafana par l’URL http://localhost:3000 , l’identifiant par défaut est admin, le mot de passe aussi.
À partir de là, je peux copier-coller le code source des trois tableaux de bord Redis pour Grafana au format JSON, disponibles depuis la page Prometheus integration6
Déploiement d’une application
Nous avons créé une base de test et y avons connecté manuellement une application de benchmark. Nous allons maintenant voir comment créer une base à valeur ajoutée avec des modules et une application connectée automatiquement sans passer les informations en ligne de commande.
J’ai créé un compte (fcerbell) et un dépôt (repository redisbank) sur DockerHub7 pour y publier l’image compilée de l’application, le temps de ce tutoriel.
Commençons par supprimer la base de test, si elle existe toujours. Redis Enterprise est multi-tenant et peut héberger autant de base de données Redis que souhaité, dans la limite des ressources matérielles mises à sa disposition et de ce qu’autorise la licence déployée. La license Redis Enterprise d’évaluation n’inclue pas d’assez de shards pour disposer de ces deux bases simultanément avec leur dimensionnement.
kubectl delete redb smalldb
Redisbank
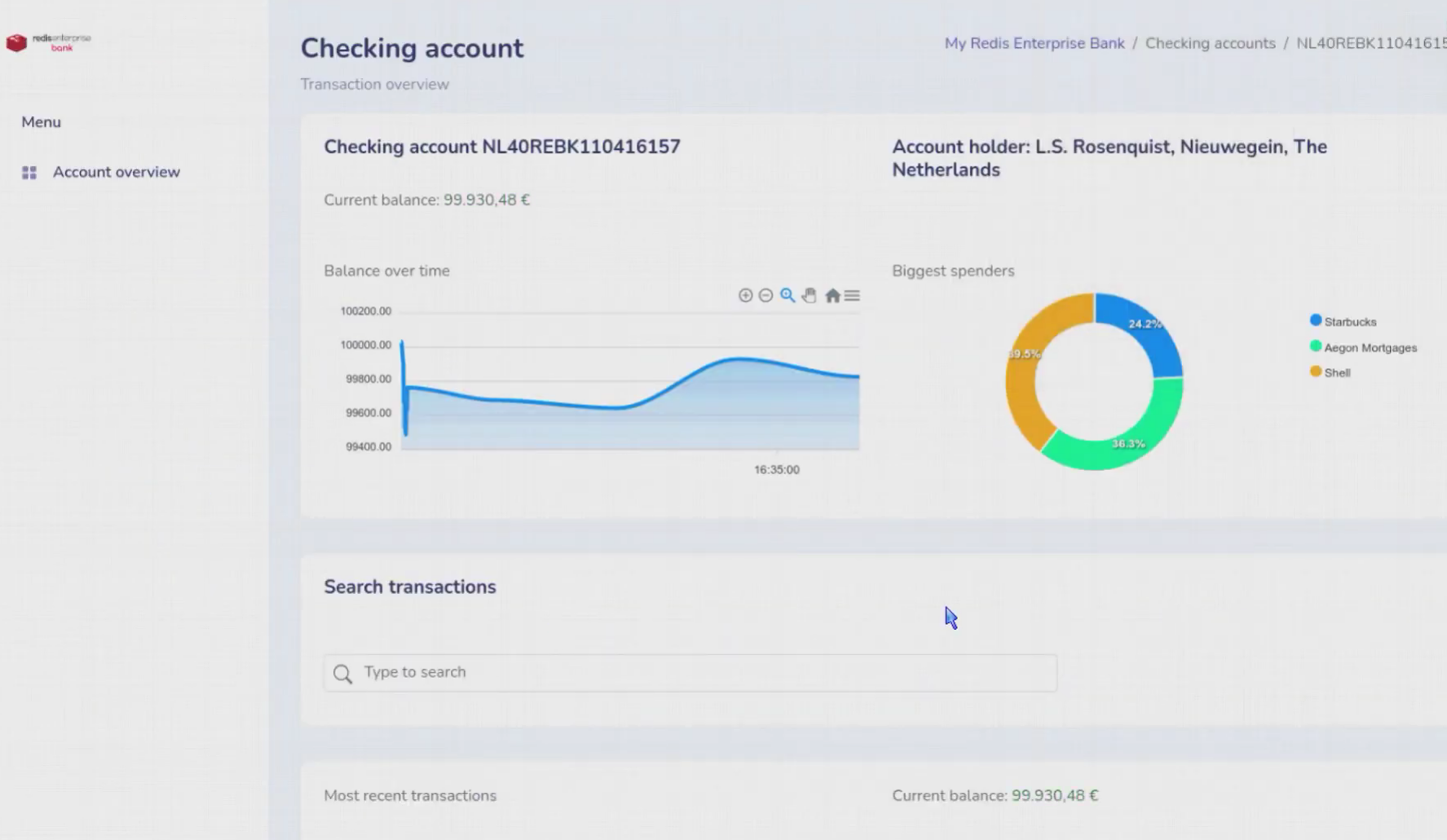
J’ai choisi une application très simple. Il s’agit d’une application monolithique en Java, utilisant le framework Spring et Spring-Data-Redis. Je commence par récupérer le code source de l’application depuis le dépôt GitHub8
git clone https://github.com/fcerbell/redisbank
cd redisbank/
Je compile l’image en l’étiquettant avec le nom de mon dépôt sur Docker Hub, je me connecte au dépôt et j’y envoie l’image compilée pour qu’elle soit disponible en téléchargement libre depuis un dépôt d’images, pour Kubernetes :
docker build -t fcerbell/redisbank .
docker login
docker push fcerbell/redisbank:latest
Je peux créer une base pour l’application. Cette base est dimensionnée sur un seul shard, et n’utilisera qu’un cœur au plus, elle est répliquée, donc hautement disponible, elle utilisera un second shard de réplication. Elle n’occupera pas plus de 1Go de RAM, soit 500Mo pour les données et 500Mo pour le réplica. Mais sa véritable particularité est de charger deux modules d’extension utilisés par l’application. Avec Redis-Enterprise, il suffit de les spécifier, charge au cluster de les trouver, de les déployer sur les nœuds où tourneront les shards et de les faire charger par les shards.
- RedisSearch est un moteur d’indexation automatique en temps réel et sans maintenance. Il permet de répondre à des requêtes de Full-Text Search (FTS), avec tokenisation, stemming, stop-words, langages, recherches floues ou approximatives, recherches phonetiques, scoring, … Mais aussi à des requêtes d’auto-complétion, des requêtes complexes avec agrégation, filtrage, ….
- Redis Timeseries permet de stocker des séries temporelles dans une structure adaptée, avec la possibilité de faire des agrégation automatique graduelles dans le temps.
```bash
cat « EOF | kubectl apply -f -
apiVersion: app.redislabs.com/v1alpha1
kind: RedisEnterpriseDatabase
metadata:
name: redis-enterprise-database
spec:
memorySize: 1G
shardCount: 1
replication: true
modulesList:
- name: “search” version: “2.4.16”
- name: “timeseries” version: “1.6.17” EOF ```
Une fois la base créée, je peux déployer l’application dans un petit pod. Cette application utilise SpringData-Redis pour se connecter à Redis. Ce framework utilise un fichier de configuration pour y trouver les informations de connexion : application.yaml. En le consultant, on voit qu’il utilise des variables d’environnement pour initialiser ces informations, si elles sont disponibles :
# Properties for running on localhost are the default
# Environment variables will be used when set
# Use these on your deployment environment of choice
stomp.host=${STOMP_HOST:localhost}
stomp.protocol=${STOMP_PROTOCOL:ws}
stomp.port=${STOMP_PORT:8080}
spring.redis.host=${REDIS_HOST:localhost}
spring.redis.port=${REDIS_PORT:6379}
spring.redis.password=${REDIS_PASSWORD:}
# Global properties
stomp.endpoint=/websocket
stomp.destinationPrefix=/topic
stomp.transactionsTopic=/topic/transactions
management.endpoints.web.exposure.include=env
spring.session.store-type=redis
spring.session.redis.namespace={lars:}spring:session
Il suffit donc d’indiquer à Kubernetes de recopier les informations de connexion depuis le Secret dans des variables d’environnement de la session exécutant l’application dans le conteneur du pod. Non seulement ces information sensibles ne transitent pas par le réseau ou par mon poste de travail, elle n’apparaissent pas dans la liste des processus, mais en plus, cette configuration est portable à travers les environnements de déploiement (Dev, Recette, Intégration, PréProd, Prod…).
cat << EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: redisbank-deployment
spec:
selector:
matchLabels:
app: redisbank
replicas: 1
template:
metadata:
labels:
app: redisbank
spec:
containers:
- name: redisbank
image: fcerbell/redisbank:latest
resources:
requests:
memory: "128Mi"
cpu: "250m"
limits:
memory: "256Mi"
cpu: "500m"
ports:
- name: redisbank
containerPort: 8080
env: ## Set app environment variables from REDB secrets
- name: SPRING_REDIS_HOST
valueFrom:
secretKeyRef:
name: redb-redis-enterprise-database
key: service_name
- name: SPRING_REDIS_PORT
valueFrom:
secretKeyRef:
name: redb-redis-enterprise-database
key: port
- name: SPRING_REDIS_PASSWORD
valueFrom:
secretKeyRef:
name: redb-redis-enterprise-database
key: password
EOF
Comme d’habitude, je crée un service Kubernetes pour manipuler l’interface web de l’application
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: Service
metadata:
name: redisbank
labels:
app: redisbank
spec:
ports:
- port: 8081
targetPort: 8080
nodePort: 30080
name: redisbank
selector:
app: redisbank
type: NodePort
EOF
Et je connecte ce service à un port de ma machine locale pour y connecter mon navigateur :
kubectl port-forward service/redisbank 8081